Created by Mahsa Paknezhad
The use of image textural analysis has obvious applications in the geosciences. Texture, be it the texture of an airborne magnetic image, a seismic section or the grain size or foliation in a rock image, is a powerful tool to extract useful information from geoscience data. There are a number of approaches to quantify and utilise textural analysis of images. Here we will look at the field of Radiomics.
Since the term was first coined in 2012, Radiomics has widely been used for medical image analysis. Radiomics refers to the automatic or semi-automatic extraction of a large of number of quantitative features from medical images. These features have been able to uncover characteristics that can differentiate tumoral tissue from normal tissue and tissue at different stages of cancer.
In this blog, we aim to show that Radiomic features can be useful for analysis of images in many other domains. The example we have provided here shows that radiomic features can be used for tree bark identification. We use Trunk12, a publicly available dataset of tree bark images from here. The code for this blog is available at this link.
Trunk12 Dataset
Trunk12 consists of 393 RGB images of tree barks captured from 12 types of trees in Slovenia. For each type of tree, there exists about 30 jpeg images of resolution 3000×4000 pixels. The images are taken using the same camera Nikon COOLPIX S3000 and while following the same imaging setup: same distance, light conditions and in an upright position. The following code plots the number of images in each class in this dataset:
import torchvision import seaborn as sns # Location of the dataset data_dir = '../data/trunk12' # Read images from the dataset directory dataset = torchvision.datasets.ImageFolder(root=data_dir) # Show the number of images in each class plt.figure(figsize=[15, 5]) p = sns.countplot(dataset.targets, palette=['#2F3C7E', '#CCCCCC']) p.set_xticklabels(dataset.classes);
The number of images in each class are shown below.
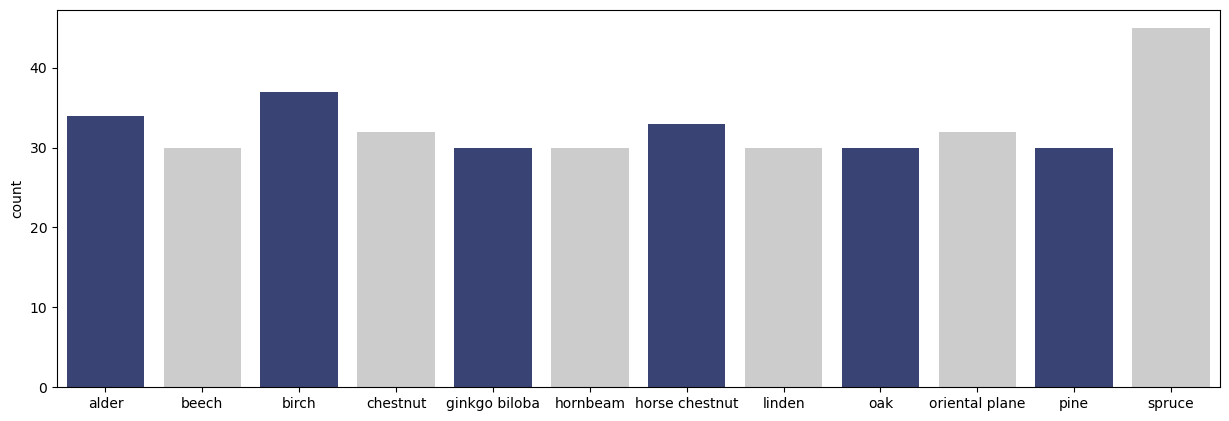
We also show a few examples of images in this dataset together with their tree type using the code below.
import torchvision.transforms as transforms import matplotlib.pyplot as plt from PIL import Image import random import torch n = 6 indices = random.sample(range(0, len(dataset.imgs)),n) batch = [dataset.imgs[i] for i in indices] trans = transforms.ToTensor() plt.figure(figsize=[15,5]) for i in range(n): img = Image.open(batch[i][0]) img = trans(img) img = torch.permute(img, (1,2,0)) target = dataset.classes[batch[i][1]] plt.subplot(1,n,i+1) plt.imshow(img) plt.title(target) plt.tight_layout() plt.show()
The output of this code is shown in the following figure:

To prepare this dataset for radiomic feature extraction we perform a few pre-processing steps on the images. These steps are explained in the following section.
Pre-processing
All images go through the following pre-processing steps. First, the images are converted to grayscale. Second, squares of size 3000×3000 pixels are cropped from the centre of images. Third, the cropped squares are down sampled to the size 250×250 pixels. Finally, image contrast is increased so that the intensity values in each image covers the range [0,255]. The pre-processing code is provided below:
import numpy as np import nibabel as nib from PIL import Image, ImageOps import os crops_s = 3000 new_s = 256 half_crop_s = int(crop_s/2) for file, label in dataset.imgs: # Open an image img = Image.open(file) # Convert it to a grayscale image img = ImageOps.grayscale(img) # Down-sample the image w2 = int(img.size[0]/2) h2 = int(img.size[1]/2) img = img.crop((w2-half_crop_s, h2-half_crop_s, w2+half_crop_s, h2+half_crop_s)) img = img.resize((new_s,new_s)) # Increase contrast of the image extrema = img.getextrema() arr = np.asarray(img).astype('float') arr = (arr - extrema[0])/ (extrema[1] - extrema[0]) * 255 # Write the image ...
Below, we show the same images that were shown above after going through these pre-processing steps.

In the next step, we extract Radiomic features from the processed images. But first we provide a brief introduction to Radiomic features.
What are Radiomic Features?
Radiomics is quantifying and extracting many imaging patterns including texture and shape features from images using automatic and semi-automatic algorithms. These features, usually invisible to the human-eye, can be extracted non-subjectively and used to train and validate models for prediction and early stratification of patients. Radiomic features are categorised into five groups of features.

These features are extracted from the region of interest in an image which is specified by a mask. We will give a brief explanation for each family of features:
Histogram-based features: These are the group of quantitative features that can be extracted from the histogram of the intensity values for the region of interest in the image. Examples of these features include mean, max and min intensity values, variance, skewness, entropy and kurtosis.
Transform-based features: Transform-based features are features that are extracted after transferring the region of interest to a different space by applying a transformation function. Such transformation functions include Fourier, Gabor and Harr wavelet transform. Quantitative features such as histogram-based features are extracted from the transformed region of interest.
Texture-based features: These features aim to extract quantitative features that represent variations in the intensities within the region of interest. Examples of features in this family of features are:

Extracting any of these features first requires specifying the direction of extraction. Any of the following directions can be selected:

As an example, extracting GLCM in the horizontal direction from a region of interest outputs a matrix. Elements of this matrix specify the number of times different combination of intensity values occur in the region of interest horizontally.

As can be seen, GLCM is not a quantitative feature per-se but quantitative features are extracted from GLCM. Some of the quantitative features that can be extracted from GLCM are shown in the table below:
| Texture Matrix | Features | Description |
|---|---|---|
| GLCM | Contrast | Measures the local variations in the GLCM. |
| Correlation | Measures the joint probability occurrence of the specified pixel pairs. | |
| Energy | Provides the sum of squared elements in the GLCM. Also known as uniformity or the angular second moment. | |
| Homogeneity | Measures the closeness of the distribution of elements in the GLCM to the GLCM diagonal. |
Model-based features: Parameterised models such as autoregressive models or fractal analysis models can be fitted on the region of interest. Once the parameters for these models are estimated, they are used as Radiomics features.
Shape-based features: Shape-based features describe geometric properties of the region of interest. Compactness, sphericity, density, 2D or 3D dimeters, axes and their ratios are examples of features in this family.
Now that we have a better idea what Radiomics features are, we will proceed with extracting these features from our processed tree bark images.
Radiomic Feature Extraction
To extract Radiomics features from our dataset of tree bark images we take advantage of the PyRadiomics library. This library can extract up to 120 radiomic features (both 2D and 3D). One limitation of PyRadiomics is that it is developed for medical images so it can only extract features from medical images with file formats such as NIfTI, NRRD, MHA, etc. These file formats usually have a header which contains information about the patient, acquisition parameters and orientation in space so that the stored image can be unambigiuosly interpreted. To address this problem, we converted our jpeg images to NIfTI images using the following hack:
import nibabel as nib from PIL import Image import numpy as np # Location of the dataset data_dir = '../data/trunk12' # Location where NIfTI images are written nii_dir = f'../data/trunk12_nii' # Open a jpeg image and write it in NIfTI format img = Image.open(jpg_filename) arr = np.asarray(img).astype('float') arr = np.expand_dims(arr, axis=2) empty_header = nib.Nifti1Header() affine = np.eye(4) nifti_img = nib.Nifti1Image(arr, affine, empty_header) nifti_filename = jpg_filename.replace(data_dir, nii_dir) nifti_filename = nifti_filename.replace('.JPG', '.nii.gz') path = nifti_filename.replace(nifti_filename.split('/')[-1], "") os.makedirs(path, exist_ok = True) nib.save(nifti_img, nifti_filename)
As can be seen, we have defined an empty header with an identity matrix for the affine transform matrix. The affine transform matrix gives the relationship between pixel or voxel coordinates and world coordinates. The same header and affine transform matrix is defined for all jpeg images in our dataset. As a result, the extracted Radiomic features from these images are comparable. PyRadiomics also requires a mask file that specifies the region of interest to extract features from in the input image. For our case, we plan to extract features from the entire image. Therefore, we generate a mask file that covers almost the whole image as shown below. The reason we don’t set the mask to cover the whole image is that PyRadiomics currently doesn’t support this.
import nibabel as nib from PIL import Image import numpy as np # Write a mask file in NIfTI format mask = np.ones(img.shape) *255 mask[:1, :1, :] = 0 mask = mask.astype(np.uint8) mask_filename = "../outputs/mask.nii.gz" empty_header = nib.Nifti1Header() affine = np.eye(4) mask_img = nib.Nifti1Image(mask, affine, empty_header) nib.save(mask_img, mask_filename)
Above, we specified the mask label for the region of interest with 255. Now, we can extract Radiomic features from the generated NIfTI images using the mask file and the mask label as shown in the following:
import radiomics from radiomics import featureextractor # Instantiate the radiomics feature extractor nifti_filename = dataset.imgs[0][0].replace(data_dir, nii_dir).replace('.JPG', '.nii.gz') extractor = featureextractor.RadiomicsFeatureExtractor(force2D=True) output = extractor.execute(nifti_filename), mask_filename, label=255)
Figure below shows the extracted features by PyRadiomics and their values from an image in our dataset:

As shown, the range of feature values is between 0 and 109. To extract radiomic features from all images in our dataset, we can generate a csv file that contains the location of all the NIfTI images in our dataset together with the mask file and mask label and pass this csv to PyRadiomics for feature extraction. The same mask file and mask label is used for all images. Below we show how the csv file is generated:
import csv import numpy as np import pandas as pd # Write a csv file that contains the location of each NIfTI image in the train set, its mask file and label pyradiomics_header = ('Image','Mask', 'Label') m_arr = [mask_filename] * len(dataset.imgs) rows = [(i[0].replace(data_dir, nii_dir).replace('.JPG', '.nii.gz'), m, 255) for m, i in zip(m_arr, dataset.imgs)] rows.insert(0, pyradiomics_header) arr = np.asarray(rows) np.savetxt('../outputs/pyradiomics_samples.csv', arr, fmt="%s", delimiter=",")
Next, this csv file is passed as input to PyRadiomics as shown below:
# Run Pyradiomics on pyradiomics_sample.csv, output to pyradi_features_3000_256.csv
!pyradiomics -o ../outputs/pyradi_features_{crop_s}_{new_s}.csv -f csv ../outputs/pyradiomics_samples.csv &> ../outputs/log.txt
This command will generate another excel sheet named pyradi_features_3000_256.csv which contains at each row the Radiomic feature values for each image in the pyradiomics_samples.csv file.
Radiomic Feature Processing
The output feature values are saved in the file pyradi_features_3000_256.csv for each image in the dataset. Now, we can open this file and have a look at it. The first 25 columns in this file contain information about parameters that were used for feature extraction. The rest of the columns contain the extracted features. This is a total of 107 Radiomic features for our dataset.
import pandas as pd # Declare csv filename from Pyradiomics (zscore scaled and merged) fname = f'../outputs/pyradi_features_{crop_s}_{new_s}.csv' # Load data pyradi_data = pd.read_csv(fname) # Show the radiomic feature columns pyradi_original = pyradi_data.iloc[:,25:] pyradi_original.head()/pyradiomics_samples.csv &> ../outputs/log.txt

As shown above, the shape feature values have the same values. This is because the region of interest is the same for all images. To train a classifier on the Radiomic features, we first need to normalize the feature values to the range [0,1] and remove those feature columns with nan values using the code below. Also, we add the tree types as the class labels to the excel sheet.
# Normalize the feature values pyradi_original_norm = (pyradi_original - pyradi_original.min()) / (pyradi_original.max() - pyradi_original.min()) # Add the class labels pyradi_original_norm['target'] = dataset.targets # Drop features with NaN values pyradi_original_norm = pyradi_original_norm.dropna(axis=1, how='all')
Removing features with nan values after normalization reduces the number of Radiomic features to 90. Visualising these features is challenging given the high dimensionality of the data, but in the below plot it is clear that the different classes of tree bark can be separated out across these features meaning we should be able to create a classifier to identify each species.

Training Classifiers and Evaluating the results
To test if we can create an effective classifier from these features we can train a number of model types using k-fold cross validation and compare the evaluation metrics such as precision, recall, accuracy and F1 score. We can then compare the results of these classifiers with the results from Boudra et al., 2018. In that paper, Boudra et al. propose a novel Improved Statistical Radial Binary Pattern (ISRBP) texture descriptor which improves over previous Local Binary Pattern descriptors in the encoding of texture from images.
Here we tested multiple models including XGBoost, SVM, random forest, logistic regression and stochastic gradient decent on our dataset and compared our results with the results of Boudra et al, 2018. We first plot the precision-recall curve for each tested model as shown below:

AP refers to average precision. Measurements are done using micro averaging
The precision-recall curves show that the SVM classifier outperforms all the other methods, including achieving better classification accuracy than the previous SOTA methods. Other evaluation metrics also confirm this conclusion.
| Classifier | XGBoost | SVM | Random Forest | Linear Regression | SGD | Boudra et al. (2018) |
|---|---|---|---|---|---|---|
| Precision | 0.660 | 0.703 | 0.603 | 0.680 | 0.513 | – |
| Recall | 0.656 | 0.699 | 0.603 | 0.679 | 0.501 | – |
| Accuracy | 0.656 | 0.699 | 0.603 | 0.679 | 0.501 | 0.677 |
| AUC | 0.935 | 0.953 | 0.914 | 0.950 | 0.751 | – |
| F1 | 0.638 | 0.682 | 0.580 | 0.663 | 0.445 | – |
All measurements are done using weighted averaging.
Conclusion
In this blog, we showed that Radiomics analysis can be as useful in other areas as it is in the medical domain. As an example, we showed how Radiomic features can help classify tree bark images. We used PyRadiomics library to extract Radiomic features from the Trunk12 dataset. Although this library can only work with medical image file formats, we showed how we can hack our way through by converting our jpeg images to NIfTI images. We then trained multiple classifiers on the extracted Radiomic features from these NIfTI images and compared their performance. Our analysis showed that training a SVM classifier on Radiomic features extracted from tree bark images gives the highest classification performance compared to other classifiers trained on the same Radiomic features and a different approach proposed by Boudra et al. (2018).
One topic that is important but not covered in this blog is feature selection. Many times, using only a few carefully selected Radiomic features can have more predictive capability than using all the extracted features. Although, using all the Radiomic feature resulted in the highest classification performance in the example in this blog, it is worth considering different feature selection methods in your projects instead of passing all the Radiomic features to your classifier.
Reference
Boudra, S., Yahiaoui, I., & Behloul, A. (2018, September). Bark identification using improved statistical radial binary patterns. In 2018 International conference on content-based multimedia indexing (CBMI) (pp. 1-6). IEEE.