Created by Jack Maughan
One of the most important components of machine learning is understanding and evaluating model performance. There are many different metrics used to assess performance across the various fields of machine learning, such as ‘accuracy score’ in supervised classification and ‘the silhouette score’ in unsupervised clustering. Each of these metrics have their own benefits and best use cases, but it can be quite daunting picking the right metric to use and knowing what it represents. This blog post discusses how common metrics are calculated in supervised regression modelling, highlighting some advantages and disadvantages of each.
To help visualise how these are calculated we will set up a problem and try to solve it using machine learning. More specifically, we’ll attempt to build a regression model that predicts surficial calcrete copper (Cu) values from airborne radiometric thorium data. A model like this could be used to interpolate/extrapolate our calcrete copper values across a study area as a potential alternative to traditional kriging methods. The data for this notebook is spatially situated in the centre of South Australia’s Gawler Craton, a highly prospective region for base metal mineralisation. Both the calcrete copper and the radiometric datasets used in this notebook were downloaded from the Geological Survey of South Australia’s SARIG portal, and were then pre-processed, aligned, and exported as .tif files using QGIS. To make visualisation even simpler, we will only focus on a subset of this data identified as zone 8 in the map below.

To get started we must first import the required python libraries for this notebook and read in the pre-processed dataset.
import warnings warnings.filterwarnings('ignore') #Importing all required packages import numpy as np import pandas as pd import skimage.io import glob import plotly.express as px import plotly.graph_objects as go from plotly.subplots import make_subplots from sklearn import metrics from sklearn.linear_model import LinearRegression from sklearn.ensemble import RandomForestRegressor
#Reading in the data and viewing the first 10 rows df = pd.read_csv('../Blogs/Data/Regression Example/Regression_Example.csv') df.head(10)
| RAD_Th | Cu_ppb |
|---|---|
| 5.999780 | 2.06 |
| 5.645620 | 2.14 |
| 5.919122 | 2.17 |
| 5.441591 | 1.98 |
| 5.062979 | 1.56 |
| 3.396205 | 1.16 |
| 4.987769 | 2.62 |
| 4.700179 | 2.62 |
| 5.166032 | 1.35 |
| 4.753295 | 0.77 |
We can see that the data is loaded as a two column dataframe, with Cu values represented in ppb units. We will initially fit a ‘Simple Regression Model’ to this data, which is a model that utilises only a single feature to predict the target variable. Commonly in simple regression, the single feature is referred to as ‘the independent variable’, ‘explanatory variable’, ‘predictor’ or more simply ‘x’, whereas the target variable is commonly known as ‘the dependent variable’ or ‘y’. In our case, Thorium is our single feature x and Cu is our target variable y. In the next cell we will plot the two features and a fitted linear regression model to visualise the relationship.
#Selecting the feature (X) and target variable (Y) from the dataset X = df['RAD_Th'].values.reshape(-1, 1) Y = df['Cu_ppb'] #Setting a range for the plot x_range = np.linspace(X.min(), X.max(), 100) #Creating the regressor model and fitting it to the data LR = LinearRegression() LR.fit(X, Y) y_pred = LR.predict(X) y_LR = LR.predict(x_range.reshape(-1, 1)) #Creating a plot fig = px.scatter(df, x='RAD_Th', y='Cu_ppb', title='Zone 8 - Linear Regression', width=1400, height=800) fig.update_traces(marker=dict(size=8)) fig.add_traces(go.Scatter(x=x_range, y=y_LR, name='Linear Regression Fit')) #Plotting the data fig.show(renderer="svg")

We can see that the red line (representing the linear regression model) fits the data in a way that suggests that as radiometric thorium values increase so does the Cu values in our calcrete samples. Assuming we are happy with this model we can use it to predict what our Cu ppb values would be for any given value of thorium. Visually we can see that this is not a bad fit for the data, but what if we wanted to know the error or uncertainty in this model or we wanted to improve it by adding more features, changing the algorithm or parameterising our existing one. Ideally, we want a way to quantitatively measure the goodness of fit and this is where model metrics come in. Common metrics that we will calculate are;
-
The Mean Absolute Error (MAE)
-
Mean Squared Error (MSE)
-
Root Mean Squared Error (RMSE)
-
Coefficient of Determination (R² or R-Squared)
-
Adjusted Coefficient of Determination (Adjusted R²)
The cell below contains a function calculating these metrics and calculates them for our linear regression model*.
*Note: In traditional machine learning the dataset is split into train/test/validation sets. The model is fit to the training data and the metrics are calculated from the testing dataset. To maintain simplicity we are fitting the regression model and assessing the metrics on the same data. This is not recommended in practice.
def reg_metrics(X, Y, y_pred): mae = round(float(metrics.mean_absolute_error(Y, y_pred)), 2) mse = round(float(metrics.mean_squared_error(Y, y_pred)), 2) rmse = round(float(np.sqrt(mse)), 2) r2 = round(float(metrics.r2_score(Y, y_pred)), 2) adj_r2 = round(1 - (1-r2)*(len(Y)-1)/(len(Y)-X.shape[1]-1), 2) print("Regression Model Performance") print("--------------------------------------") print(f'Mean Absolute Error (MAE) is {mae}') print(f'Mean Squared Error (MSE) is {mse}') print(f'Root Mean Squared Error (RMSE) is {rmse}') print(f'Coefficient of Determination (R2) score is {r2}') print(f'Adjusted Coefficient of Determination (Adj R2) score is {adj_r2}') #Run the function on our linear regression results reg_metrics(X, Y, y_pred) Regression Model Performance -------------------------------------- Mean Absolute Error (MAE) is 0.32 Mean Squared Error (MSE) is 0.16 Root Mean Squared Error (RMSE) is 0.4 Coefficient of Determination (R2) score is 0.45 Adjusted Coefficient of Determination (Adj R2) score is 0.44
Here we can view the metric scores for our model, but what do these scores actually represent? Before we delve into the individual formulas used for calculating each metric, we’ll first need to introduce and understand the definitions of y-hat (Ŷ) and residuals. As mentioned above, we can now use our linear regression model to predict the value of Cu from any thorium value. This includes predicting the values of Cu that we already know the true values for. In other words Knowing that we have the y values used to build the model, we can compare them to the values that the model predicts for the same value of x. This value is called y-hat and the image below shows 3 examples of what our actual y value is and what the predicted y-hat value is.

The difference (vertical pink line) between y and y-hat is known as the residual, and is the basis for the all of the validation metrics we will cover. However, metrics take into account every single residual of the model which in our case looks like the following:

Now that we have and understanding of y-Hat and what residuals are we can calculate some metrics.
Mean Absolute Error (MAE)
The Mean Absolute Error is a simple yet tried and true method of determining model robustness and it can be defined in the following equation.

Where MAE is equal the the sum of all n absolute residuals, divided by the total number of residuals (multiplied by 1/n in this case) to get the mean absolute score. It’s important to get the absolute value of each residual before summing them together, otherwise the summation will involve both negative and positive values that cancel each other out. The MAE value can range from 0 to infinity and an advantage of this metric is that the units are the same as the target variable, making it easier to understand the results. So in this case, when we say our MAE is equal to 0.32, it means that the model will give an error of approximately 0.32 ppb for each prediction of copper in our study area.
Mean Squared Error (MSE)
The Mean Squared Error is very similar as the MAE, except instead of taking the absolute value of the residual we take the squared value of the residual, as per the equation below.
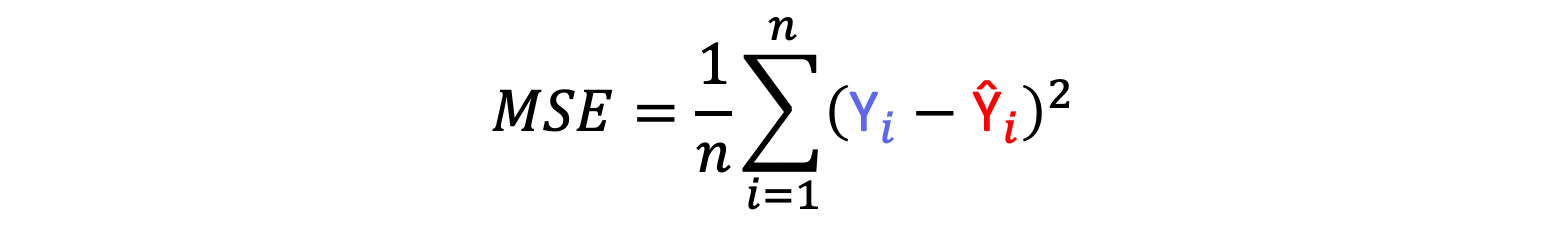
In this case we don’t need to worry about positive and negative residuals cancelling each other out as once the values are squared they become positive. A different way to to view this error value is to visualise the squares given from this error.

The above image shows the squared error for 3 example residuals. Now imagine that every residual has a respective square. The MSE is the sum of the area of each square divided by the total amount of residuals n. As seen from our function, our regression example has a MSE of 0.16 with units of 0.16 ppb². This doesn’t really make much sense in regard to our units. The RMSE is heavily penalised by outliers due to their significantly large square value. Another metric we can look at is the Root Mean Squared Error.
Root Mean Squared Error (RMSE)
As the name suggests, the Root Mean Squared Error is just the square root of the MSE.

The RMSE is not as heavily penalised by outliers as the MSE, but compared to MAE they are still not as robust. The error value units are again the same as our target variable, where in this case the RMSE for our linear regression model is equal to 0.4 ppb Copper.
Coefficient of Determination (R²)
The Coefficient of Determination or the R-Squared (R²) value is a very commonly used metric for evaluation. Unlike the MAE, MSE and RMSE, the R² value is independent of context, meaning that the resultant value is not related to the ppb units. The R² value can be calculated from the following equation.
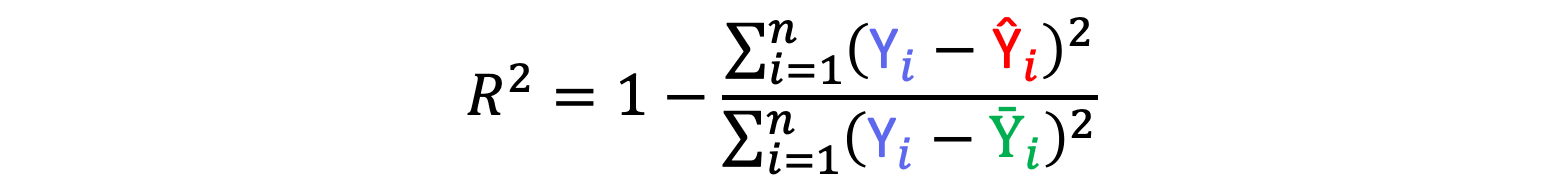
It appears a bit more maths heavy than the equations of our other metrics, but in reality its still quite a simple calculation. Firstly we need to address our freshly introduced variable Ȳ. Ȳ (or y-bar) is equal to the average of all observed y values. The numerator component of the fraction is known as the residual sum of squares (RSS), which is the sum of all the residual values squared, and the denominator component is known as the total sum of squares (TSS). The TSS is the the sum of each values difference to the mean squared and is entirely dependent on our data, meaning it will not change when we alter our model. RSS on the other hand will change as the y-hat values will be altered when the model is altered. The R² equation can be simplified as;
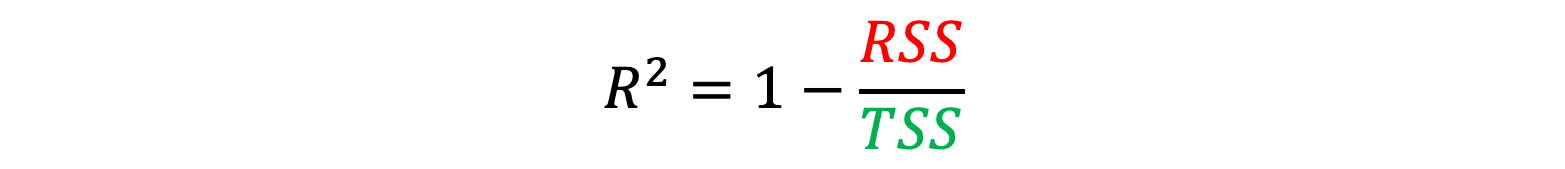
A way to visualise the difference between RSS and TSS is shown in the image below. The better our model fits the data, the lower the RSS value becomes and in turn the RSS/TSS value will become lower and our R² value will head towards 1. The resulting values range from 0-1 where 1 is a perfect fit. In this case of the linear regression our R² is equal to 0.45.

Adjusted Coefficient of Determination (Adj R²)
The final metric we will look at is the Adjusted Coefficient of Determination or the Adjusted R² value. As the name suggests this metric is built off of the R² score but with a slight twist. The adjusted R² score takes into account the number of samples in the data set and the amount of features used. The equation for this metric is:

Where Ns is equal to the number of samples and Nf is equal to the number of features. The benefit of using the adjusted R² value is that it ‘adjusts’ the score when features are added, either increasing for useful features or decreasing for less important features. This is different to the R² value which can only increase as features are added. We can see that if Nf increases but R² and Ns stays the same, the Adjusted R² value decreases, suggesting that adding features to the model is not increasing the original R² value and is probably causing harm due to overfitting. However, if the original R² value is increasing with the added features, the Adjusted R² value does capture this information, making it a very useful metric.
We can visualise this in the following plot, where if we keep the R² score at a constant value of 0.7 (meaning no improvement to the model) and the number of samples at a constant value of 150, we see that adding more features decreases the adjusted R² score.
#Setting a constant R^2 and number of sampled r2 = 0.7 Ns = 150 #Generating a varying range of feature numbers and adjusted R^2 var_Nf = np.linspace(5, 50, 10) var_Nf_adjr2 = [1 - (1-r2)*(Ns-1)/(Ns-Nf_i-1) for Nf_i in var_Nf] #Plotting points fig = make_subplots(rows=1, cols=1) fig.add_trace(go.Scatter(x=var_Nf, y=var_Nf_adjr2), row=1, col=1) fig.update_traces(marker=dict(size=8)) fig.update_yaxes(title_text="Adjusted R^2 Value", row=1, col=1) fig.update_xaxes(title_text="Number of Features", row=1, col=1) fig.update_layout(height=600, width=1000, title_text="Varying Number of Features with Constant R^2") fig.show()

Which one to choose?
Now that we’ve checked out 5 common evaluation metrics for regression models, which one do we choose to assess performance? There’s no right answer to this question, and as each metric calculates a slightly different thing it’s good practice to assess them all. Some important notes for each of the metrics are:
-
MAE – Score units are in the same units of the target variable, all residuals are weighted equally
-
MSE – Strongly influenced by outlying values and units are in squared form
-
RMSE – More robust to outliers than MSE, but still penalises outliers with large errors. Score is in same units as target variable
-
R² – Will always be 1 or less (closer to 1 the better) and independent of variable context
-
Adjusted R² – An improvement on R², inclusive of how the number of features and samples affect model performance
For some more in-depth evaluations on these metrics check out these links:
-
Regression: An Explanation of Regression Metrics And What Can Go Wrong
-
Choosing the Right Metric for Evaluating Machine Learning Models
Final comments
To explain the model metrics we only looked at a single feature using a simple regression model, but all these metrics can be calculated from any regression model using any number of features. For the final part of this notebook lets look at how a random forest regressor would look if we fit it to our data.
#Setting the RF regressor RF = RandomForestRegressor() #Fitting the model to our data RF.fit(X, Y) #Predicting our data y_pred = RF.predict(X) y_RF = RF.predict(x_range.reshape(-1, 1)) #Plotting the results fig = px.scatter(df, x='RAD_Th', y='Cu_ppb', title='Zone 8 - Random Forest', width=1400, height=800) fig.update_traces(marker=dict(size=8)) fig.add_traces(go.Scatter(x=x_range, y=y_RF, name='Random Forest Fit')) fig.show()

We can see that the random forest regression model (red line) is more granular in explaining the relationship between Cu and radiometric Th. As the model is still just a single line representing this relationship, we can calculate the regression metrics in the exact same way as linear regression. The image below shows the residuals for this model in which our metrics are calculated and we can see that it visually is performing better than our initial model.

reg_metrics(X, Y, y_pred) Regression Model Performance -------------------------------------- Mean Absolute Error (MAE) is 0.15 Mean Squared Error (MSE) is 0.04 Root Mean Squared Error (RMSE) is 0.2 Coefficient of Determination (R2) score is 0.88 Adjusted Coefficient of Determination (Adj R2) score is 0.88
As expected, there is a significant change in our model metrics. The MAE, MSE and RMSE have all dropped, and the R² and adjusted R² have increased indicating that this model is better at predicting Cu values than our linear regression model. However, this is where subject matter expertise and geoscientific knowledge is crucial. Just because our model metrics have improved, does this mean it is any better at explaining the relationship between Th and Cu values in calcrete samples? Should we expect to see a large peak of Cu values at values of 6.8 ppm Th or is this peak due to an overfit model? Keeping in mind we have not split our data into train and test sets for overfitting/underfitting evaluation and that we have not taken into account spatial auto-correlation this is almost definitely the case. So although we have a significant increase in model performance according to our metrics, there are still a large number of external factors to take into account when deciding if a model is useful or not, but that can of worms will have to wait for next time.